Sam add some case studies to coordination design problem space.
Coordination Problems
Leave a reply
Sam add some case studies to coordination design problem space.
How to increase your tip (I bet these work for increasing your bonus too).
| 17% | Wearing a Flower in Hair |
| 53% | Introducing Self by Name |
| 20% | Waiter Squatting Down Next to Table |
| 25% | Waitress Squatting Down Next to Table |
| 100% | Repeat Order Back to Customer |
| 140% | Smiling |
| 23% | Suggestive Selling (aka upselling) |
| 42% | Touching Customer, Study 1 |
| 27% | Touching Customer, Study 2 |
| 22% | Touching Customer, Study 3 |
| 28% | Touching Customer, Study 4 |
| 40% | Tell a Joke (to entertain customer) |
| 18% | Give a Puzzle (to entertain customer) |
| 18% | Forecast Good Weather |
| 13% | Writing “Thank You” on Check |
| – | Waiter drawing smiley face on Check |
| 18% | Waitress drawing smiley face on Check |
| 37% | Bartender drawing sun on Check |
| 25% | Restaurant, Using Tip Trays w/ Credit Card Insignia |
| 22% | Cafe, Using Tip Trays w/ Credit Card Insignia |
| 18% | Give Customer Candy, Study 1 |
| 21% | Give Customer Candy, Study 1 |
| 10% | Call Customer by Name |
Providing great service is not on this list because studies show measures of service quality as reported by customers is not particularly coorolated with the size of the tip left. Don’t be fooled, tips do not create a feedback loop that improves service.
Tips are an odd epilog to a transaction. The buyer gives a gift to to the seller, or is it the seller’s agent he gives a gift to? There are experts out there on every aspect of commercial transactions. The expert on tipping is Michael Lynn a Cornell. That table is gleaned from his pamphlet MegaTips. I read that 21 Billion dollars of tips are given every year in the US. So a huge proportion of the income at the low end of the income ladder are these gifts.
Like all gift scenarios it’s hard to be sure who’s getting what from the transaction. But it appears that the buyers are buying something with their tips, i.e. appear to be buying a relationship with the server. It maybe they are trying to weaken this agent’s loyalty to his employer. What is clear is that if the buyer is convinced that the server likes them then the buyer will tip well.
I doubt you will be surprised to learn there are efforts to change the “standards” about tipping. It’s a great example of how many players get involved when ever you try to shaping an exchange standard. Restaurant owners and service personel would prefer that the “standard tip” be higher. I was taught as a child that the standard tip is 15%, but the industry is working to let it be known that the standard tip is 15% to 20%. Some dead beat segments of the population known to be lousy tippers. The industry appears to be working on that.
While owners and servers both want higher tips their solidarity around this part of the transaction falls apart moments later. Owners would like minimum wage laws to include tips, servers of course don’t. Recently Rick Santorium tried to stick a clause into the bankruptcy bill to force that change upon states, shortly after getting a big tip from a resturant chain.
I liked this paper that tries to draw connections between attributes of national character and variablity in tipping across nations. The conclusions strike me as tenuous, but they certainly are fun. Anxiety, status seeking, and masculine personality in your nation increases the level of tipping.
Personally I find tipping, and certain kinds of bonuses, to be very corrosive to professionalism.
I’m not aware of any software exchange protocols that include a tip phase. DNS has a way that the server can throw in some free extra answers to questions that he suspects that the client will desire. There must be some senarios where it would be useful for the client to toss in some extra gift as he’s closing the connection.
 The web spread out so fast because HTML was so lame even a monkey could understand it. That simplicity created a low barrier to entry. Monkey see, monkey do learning was the key. A million monkeys at a million keyboards and a few years later … boom!
The web spread out so fast because HTML was so lame even a monkey could understand it. That simplicity created a low barrier to entry. Monkey see, monkey do learning was the key. A million monkeys at a million keyboards and a few years later … boom!
Even before the war buffs could turn around in their lawn chairs the long running standards war over document formats was transformed. It took Microsoft years to displace Word Perfect from the rich farm lands. It’s took Adobe years carve out an encampment on the high ground above Microsoft Word. Suddenly HTML was in control of the seas.
Bill Gates onces said of Netscape that they owned all the river front property. But, the HTTP and HTML were the water and owning those was harder. Not that they both didn’t try to own them.
Spreading fast creates very fragmented markets. The entire middleware industry is a side effect of this. Building a custom niche oriented authoring tool, say a bridge from your real time control system into the web, was the work of a weekend. Happy monkey.
Diffuse big markets call out to be condensed. They call out to capitalists to be owned. They call out to engineers to be made safe and efficent. They call out to the monkeys to come join in the fun, and those monkeys start demanding regulations, police, schools, etc.
One road to condensation is to roll up the big monkey firms, the ones that have found important bits of real estate in the new jungle. This is, for example, what Adobe is doing in buying Macromedia. Adobe likes the high ground, the sophisticated elegant page layouts and such, and Macromedia is it’s closest competitor for that ground. Flash is more widely deployed than the Adobe reader; end of story. Buying up the big monkeys isn’t an effective tactic if the new ones appear faster than you can buy them.
Another way to condense a difuse market is to raise barriers to entry. But, how do you raise the barriers to entry around HTTP and HTML? Easy. Make them more complex.
For HTTP the answer is SOAP, WS, et. al. You create a specification that is sufficently complex it scares off little monkeys. Frustrate their desire to whip off an implementation over a week end. It’s not clear this tactic is working; the value add of these stacks just isn’t as overwhelming at it needs to be.
For HTML the answer is DHMTL, XML, Javascript etc. This tactic is working out pretty well.
The idea is to make raise the barriers so the monkeys will wander off and find something else to play with. View source used to be a lot more fun for a lot more monkeys than it is today.
This is a story about standards. Simple low barrier to entry standards can spread like wild fire over an ecology. After the burn there begins a progression toward increasing complexity. Some players in the forest society will work to increase the complexity. Their motives vary. Some do it to for fun or to address real needs. Sometimes, particularly inside proffesional standards bodies, the complexity rises because the process tends to compromise to the sum of all features.
For some players the rising complexity is a conscious attempt to prepare the forest for something more suitable for their big agriculture of monoculture crops.
My theory is that exchange standards create networks and those networks exhibit power-law distributions. How skewed that is depends on principally on the regulatory framework around the exchange standard. Currency systems are a fine example of a exchange standard. There have always been numerous ‘currency substitutes;’ for example in the US we have coins, checks, credit cards, etc, etc. (see “war in my wallet“).
The check clearing system has a number of clearing houses. One of these is NACHA, an automated clearing house. Today’s chart shows the total transactions received by the top 50 financial institutions (pdf) connected to NACHA. This top 50 account for more than 90% of the traffic thru the exchange, and the top five account for more than 50%.
Banking is an interesting case because in the US we were very suspicious of banks so we regulated them to assure they were plentiful and small. But we seem to have gotten over that. For example interstate banks are recent development. Banking is rapidly condensing.
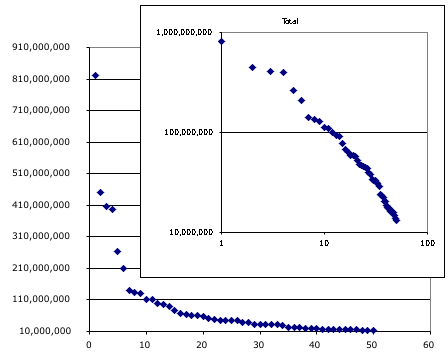
There is one point for each financial institution. The total transactions received on the vertical axis. The horizontal axis is the institution’s rank. One graph is linear. The smaller one is log-log there the line’s slope is -1.133.
Here is the analogous chart for the institutions that originated the transactions; the slope of the line on log-log graph -1.397. Originators is more condensed.
 Between producers and consumers you need to insert some sort of exchange, a trusted intermediary. I’ve always liked the way that people draw this as a cloud. It suggests angels are at work, or possibly that if you look closely things will only get blurry and your glasses will get wet. Even without getting your self wet things aren’t clear even from the outside. For example what do we mean by trust? Does it mean low-latency, reliability, robust governance, low barriers to entry, competitive markets, minimal concentration of power – who knows?
Between producers and consumers you need to insert some sort of exchange, a trusted intermediary. I’ve always liked the way that people draw this as a cloud. It suggests angels are at work, or possibly that if you look closely things will only get blurry and your glasses will get wet. Even without getting your self wet things aren’t clear even from the outside. For example what do we mean by trust? Does it mean low-latency, reliability, robust governance, low barriers to entry, competitive markets, minimal concentration of power – who knows?
 There are some leading design patterns for working on these problems. Sometimes the cloud condenses into a single hub. For example one technique is to introduce a central hub, or a monopoly. The US Postal system, the Federal Reserve’s check clearing houses, AT&T’s long distance business are old examples of that. Of course none of those were ever absolute monopolies; you could always find examples of some amount of exchange that took place by going around the hub – if you want to split hairs. Google in ‘findablity’, eBay in auctions, Amazon in the online book business are more modern examples.
There are some leading design patterns for working on these problems. Sometimes the cloud condenses into a single hub. For example one technique is to introduce a central hub, or a monopoly. The US Postal system, the Federal Reserve’s check clearing houses, AT&T’s long distance business are old examples of that. Of course none of those were ever absolute monopolies; you could always find examples of some amount of exchange that took place by going around the hub – if you want to split hairs. Google in ‘findablity’, eBay in auctions, Amazon in the online book business are more modern examples.
In the blog update notification space the hub originally was weblogs.com, but for a number of reasons it didn’t retain that role. Today the cloud’s structure is kind of lumpy. There are lumps on the producer side and the consumer side. On the producing side all the majors have aggregated a supply of pings; for example Typepad presumably has a huge supply of pings, WordPress comes out of the box pinging Ping-o-matic. On the consuming side big players aggregate pings as well, some of these are evolving toward or are explicitly in the role of intermediaries. The blog search sites are a good example (Pubsub, Feedster, Technorati). They all labor to discover fresh content. The trends seems to be toward condensation. Industries in this situation often, given time, create some sort of federated approach.
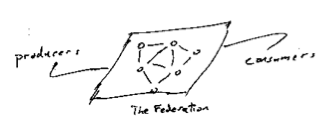 Federated approachs are clearly more social than hubs. In markets where the participants are naturally noncompetitive they can be quite social. For example when national phone companies federate to exchange traffic, or small banks federate to clear checks or credit card payments. That can change over time, of course. The nice feature of a federated architecture is that it helps create clarity about where the rules of the game are being blocked out. How and who rules the cloud is part of the mystery of trust.
Federated approachs are clearly more social than hubs. In markets where the participants are naturally noncompetitive they can be quite social. For example when national phone companies federate to exchange traffic, or small banks federate to clear checks or credit card payments. That can change over time, of course. The nice feature of a federated architecture is that it helps create clarity about where the rules of the game are being blocked out. How and who rules the cloud is part of the mystery of trust.
There is a third school of design for the cloud, what might be called “look mom no hands” or maybe technology magic. The first time I encountered that one was the routing algorithms for the Arpanet; but that’s another story. These techniques go by various names; just to pick a few P2P, distributed hashing, multicast. The general idea for these is that the N participants all install a clever lump of code; these clever bits then collaborate (using elegant ideas) and a routing network emerges that makes the problem go away.
 The magic based solutions have great stories or illustrations to go with them. For example the early Arpanet architecture had each node in the net act advertise it’s service to it’s neighbors who would then shop for the best route – boy did that not work! I worked on on three multiprocessors in the 1970s that had varing designs for how to route data between CPU and memory. One of these, the Butterfly, had a switched who’s topology was based on the Fast Fourier Transform.
The magic based solutions have great stories or illustrations to go with them. For example the early Arpanet architecture had each node in the net act advertise it’s service to it’s neighbors who would then shop for the best route – boy did that not work! I worked on on three multiprocessors in the 1970s that had varing designs for how to route data between CPU and memory. One of these, the Butterfly, had a switched who’s topology was based on the Fast Fourier Transform.

Recently I’ve been reading some papers about a system that uses what you might call fountain routing. All the nodes are arranged as peers around a circle. Packets bounce thru a few nodes to get where they are going. Each node has a few paths to distant parts of the circle and more paths to it’s neighbors. The illustration shows one node’s routes. A packet entering at that node would get thrown toward a node closer to it’s destination that node will have more routes to even closer nodes.
The monopoly/hub designs are social only to the extent that a monarchy a social structure. The federated designs are social in the manner of a town meeting or the roman senate. The technical magic solutions are social in the sense the sense that they take as a given that everybody will sign up to the same standard social contract. Each of these social architectures has it’s blind spots. For example the federated design can easily lock out small players because they can’t get a seat at the table. Magic technical solutions seem to break down when the traffic patterns stop behaving what ever their designers presumed. E.g. as the blogging example demonstrates the real world is rarely high trusting, random, uniform, collaborative, and peer to peer.
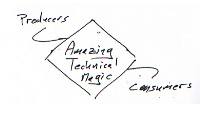
Off an on for the last few months I’ve been playing with the problem of how web sites notify their reader  when they have fresh content. This is sometimes called the Ping problem. Sometimes it’s called push, to contrast it with the typical way that content is discovered on the net i.e. pulling it from it’s source. The problem interests me for an assortment of reasons, not the least of which is that it’s a two sided network effect. On the one side you have writers and on the other side you have readers. I draw a drawing like the one on the right for situations like that. Two fluffy clouds for the producers and the consumers connected thru some sort of exchange.
when they have fresh content. This is sometimes called the Ping problem. Sometimes it’s called push, to contrast it with the typical way that content is discovered on the net i.e. pulling it from it’s source. The problem interests me for an assortment of reasons, not the least of which is that it’s a two sided network effect. On the one side you have writers and on the other side you have readers. I draw a drawing like the one on the right for situations like that. Two fluffy clouds for the producers and the consumers connected thru some sort of exchange.
The design problem that I find fascinating is the exchange. For example you could build a single hub, or a peer to peer system, or possibly something based on standards. Lots of choices both technical, social, and economic.
The set of producers has some very exceptional members. For example if you limit the problem to just blogs then Blogger and Typepad together probably account for a huge slice of the pie. Similarly some consumers have a huge appetite for content. Google, Technorati, Feedster, etc. want to read everything! These two populations are skewed, i.e. their power-laws. I draw a picture like this to illustrate that.

The blogging example provides a nice case study for the more general problem. In that community we currently have two standard solutions to the problem. Both don’t scale. Ping, which let’s producers notify a handful of sites when they update, was originally designed to notify a single site (and now a handful of sites) of updates. While it serves the voracious readers well it doesn’t scale up to help the rest of the readers. So the rest of the readers use polling to check if sites have changed. It’s a curious counter point that polling is a pain in the neck for the elite producers; in effect it enlists the long tail of readers into a denial of service attack on them.
While it’s not hard to construct conspiracy theories when working on problems like this, it is also foolish to ignore that powerful winner take all games are in the room. The shape of the distributions creates that high stakes game. It’s critical that the design take the distributions and traffic patterns into account. The Ping/Poll design is that it’s elites on the consuming side benefit while the elites on the producer side suffer. I’d be amazed if that was intentional!
Fascinating problem.
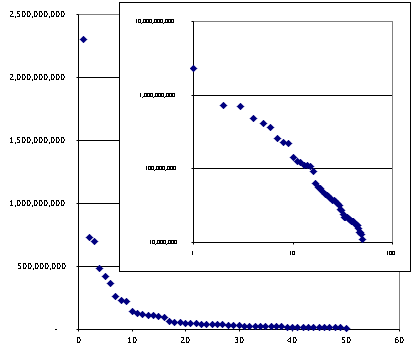
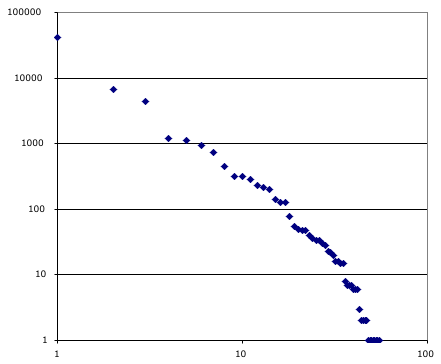 The chart at right has a dot for each open source license used by a project at source forge. Note this is projects, not installed base. I am not aware of good data for installed base. A typical power-law distribution.
The chart at right has a dot for each open source license used by a project at source forge. Note this is projects, not installed base. I am not aware of good data for installed base. A typical power-law distribution.
All the usual forces are in play that would lead toward that. Preferential attachment for example means that licensing choice is can be modeled as nothing more than mimicry of the current license distribution. Then there is the multiplicative process where new projects evolve out of the substrate of old projects, tending to bring along their own licenses. Finally there is a certain amount of condensation where projects find it advantageous to adopt similar or identical licenses for functional reasons, e.g. the lawyering to figure out if license #12 is compatible with license #17 is enough to drive most reasonable men insane.
While those forces are far more determinative in driving this distribution than the functional distinctions between the licenses once the distribution emerges the distinctions between leading licenses become clear because that’s what you have to lawyer out. Like the distribution of human languages the installed base tends to be very hard to migrate; short of disruptive displacement of entire cultures.
It saddens me. Not that we have all this diversity, that’s to be expected. What saddens me is that we, the open source community, seem to get fixated on hair splitting about the distinctions between these licenses.
These licenses are a very high risk experiment. They are an attempt to find a means to create a durible vibrant commons. Something that will stand the test of time. Something that will be useful to everybody. While we have a lot of very smart people working on finding a solution to this problem we won’t know if we found it until much much latter in the game. In games with lots of risk and little certainty diversity is an very good thing.
It is a bad idea to put all our eggs in one basket. Oh sure, too much diversity would be a pain both in mounting out defenses well and in the cost of tedious lawyering about capability. But! I deeply wish we would all try a bit harder to respect and admire the choices that each license community is making as they run their experiment. People should back off on being some damn certain they have the future by the balls. I fully expect that over the years some of these models are going to turn out to be impossible to defend from those who would privatize the commons.
We are all on the same side here, right?
By now we all have come to understand that links are a unit of currency. The number of inbound links you have, the number of customer accounts, the number of subscribers to your site’s feeds are all metrics that denote something about how successful your doing. In turn we know that links create graphs and graphs of links often have power-law distributions with amazing class distinctions betwix the parties in the graph. We know those class distinctions are not a consequence of the merit or value created by the links but instead of how fast the graph is grown or how the nodes merge as market share is rolled up thru mergers. So we know a lot about links as elements in the process of creating wealth. Every scheme for creating links will become the target of bad actors.
We also know that links play a role in the identity problem. That the more you know about a persons links the more accurate your model of him can be. We know that accurate models of users are fungible. A better handle on who the user is enables targeted advertising and more highly discriminated pricing. A better handle on who the user is enables transaction costs to be reduced. Single sign on, one-click purchasing, automated form filling are not the only examples of that.
It surprises me that we need to be reminded of this each time we encounter another effort to create a means to creating a large quantity of links.
This month’s contribution to the let me help establish a mess of links party is one-click-subscription. The puzzle in this case is how to lower the barriers to subscribing to a blog. Solving this problem requires moving three hard to move objects – all the blogs, all the readers, and sticking something in the middle between them. Both suggested solutions need to move all three; but they vary in where they put their emphasis. The blog hosts are probably the easiest of the three to move – they have an incentive to move and the market is already very concentrated.
One plan is the classic big server in the sky plan. Everybody rendezvous around the hub server. Requests to subscribe are posted to the hub. The user’s reader keeps it’s subscription set in synch with the hub. The business model suggested is a consortium organized by the common cause of a stick – fear of somebody else owning this hub – and a carrot – the bloom of increased linking it would encourage. Since early and fast movers will capture power-law elite rewards in such linking build outs there are some interesting drivers to build the consortium. Large existing players should find it advantageous to get on board. The principle problem with this plan is it’s a bit naive. A consortium of this kind is likely to become player in any number of similar hub problems, for example identity. This hub will have account relationship with everybody. It would know a lot about everybody’s interests. To say the least, that’s very hotly disputed territory. This plan has triggered more discussion than the following plan.
The second plan that’s been floated is to introduce into the middle a standard which blogs can adopt and readers can then leverage. This implies changing the behavior of most of the installed base of blog readers. The structure of that installed base is less easily shifted. The idea is to have the subscribe button return a document to the client’s browser (or blog aggregator/reader) which describes how to subscribe. Automation on the reader side can then respond to that information. This means introducing and driving the adoption of a new type of document, a new MIME type. It probably means installing a new bit of client software on everybody’s machines. The browser market leader would have some advantages in making this happen; and could there for very likely coopt any success in this plan to drive users to use his aggregator. But then that may only point out that the only reason we have a vibrant market of blog reading solutions is because the dominate browser has been dormant for a few years.
These are hard problems, and this is only one of many we currently face.
I’m not sure why this paper is called ‘Viral Communications” (pdf) but it’s fun and two things leapt out at me.
Future Proof: “Upon installation, the purchaser will have the expectation that they should work for the expected lifetime of the device itself independent of any other changes in the … environment.”
“… a commons where each new cow adds grass.”
I need to go back and add “future proof” to the reasons why people standardize; it’s a varation on what I call there “prevent stranding.” The cow line is a nice way of framing the club-good boundary maintenance problem.
My problem with the term ‘viral communications’ is that it’s so similar to ‘viral marketing.’ I know what viral marketing it; it’s marketing communication that manages to parasite on somebody else’s communication and there by captures some legitimacy which it can use to get past the recipient’s defenses against marketing. The paper is about systems of collaborating devices that use a modicum of coordination to create scalable distributed networks with lots of bandwidth. The vision is to use standards (the ones that guide that collaboration) as a substitute for the lawyers at the FCC.
I think I’m noticing something I’d not noted before about the statistics of the populations served by the standard. Some standards don’t scale the way you might expect them to. For example the B2B standards written in the 1980s and 1990s have not scaled. They are not used by small businesses. Bear with me as I build some substrate.
Exchange standards provide efficiencies for the transactions between parties. If we all adopt a similar handshake then we can have more handshakes at lower cost. Next up world peace.
In thinking about standards you can focus down on the details of the single exchange, but I find it more fascinating to shift up and think about the populations involved with the standards. For example consider selling a house. Down in the details you can pick apart the process steps taken by a buyer, seller, and middleman they do the transaction. Stepping back, at the real estate market level, look consider the three populations: house buyers, home sellers, and real estate agents.
Statistics gives us tools to talk about these populations. Even the simple statistics can illuminate some interesting things. For example we know that small populations are easier to organize and coordinate. In our example the smallest population is the real estate agents. When society comes to negotiate the rules (aka standards) for home sales the agents are much more likely to get their desires fufilled because they have an easier time getting their act together. The smallest of the three populations in any standard setting scenario have an advantage. That is a political reality.
Another simple statistic: some members of the population do more exchanges than others. The surprising fact is how skewed that is usually is. Some members do a lot more exchanges than others. Again and again when you look at the populations around these exchange standards you find a power-law distribution.
A cartoon approximation of a power law curve splits the population into two groups: the elites and the masses. In the blogging world they call the elite bloggers the A-list. (Sidebar about the risk of cartoons. This crude approximation is blind to the middle class. Blindness can do harm and so can approximations. That said, we return to the fun of this cartoon.)
The small size of the elite population has a political consequences exactly like the small population of realtors. The large transaction elite have power. For example, returning to the rules around real estate sales again, we can look at the population of house sellers for a high volume player – i.e. real estate developers. Not surprisingly they show up at the table to help set the rules.
Ok, so back to the to seemingly new thing.
What I’m noticing today is that there seems to be some very interesting to say about what happens about the correlation between two population statistics.
What happens if the elites tend mostly to exchange with only with each other? That’s what happened with the B2B standards that were written in the 1980s and 1990s. Large businesses recognized the benefits of getting standards in place to improve their efficiency. So they wrote all these standards to fit their needs. Today lots and lots of commerce takes place intermediated by those standards; but the majority of that commerce doesn’t involve small economic entities.
It’s probably worth ringing all the changes here, but that’s a project for another day. For example you get a particular kind of standard when there is a small concentrated elite on one side exchanging with a huge diffuse lower-class on the other.
If a standard is designed with only one class of players, large transactors say, then it won’t be well suited to the needs of the players who were not there when it was designed. I think that’s a very interesting insight.
Let’s go back to the example of the B2B standards designed in the 1980s and 1990s. Consider this design question: “How hard/expensive should it be to adopt this standard we are designing.” The answer the elites gave was “No more than two expert consultants for 3 months.” The answer the masses would have given: “Oh, $49.95 would be acceptible.” There is a third group at the table. The guys that design and implement the standards, i.e. the vendors. Their answer is always “As much as possible.” So the B2B standards of that era got designed with a high adoption cost, i.e. they are standards with very high barrier to entry.
This doesn’t always happen. Sometimes a standard comes out of the masses. As SMTP or HTTP did. Small players solving a problem that then got widely adopted. Such standards have their own problems; for example they may not scale well for the traffic patterns that the elite players experience. If you fear the power-law’s tendency to concentrate power you might like this kind of standard. If your trying to consolidate a market you might prefer the other kind of standard making.