Network effects. By definition, the utility function of a product with network effect is dominated by a term that grows with the number of users of that product. For example a phone is more valuable than a intercom entirely because there are more users on the otherside of the telephone network than there are users on the other end of an intercom.
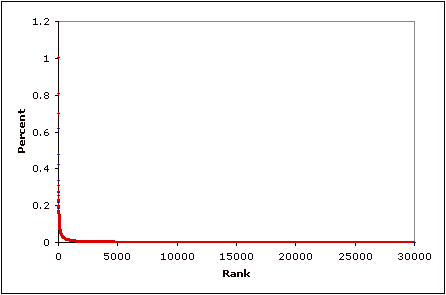
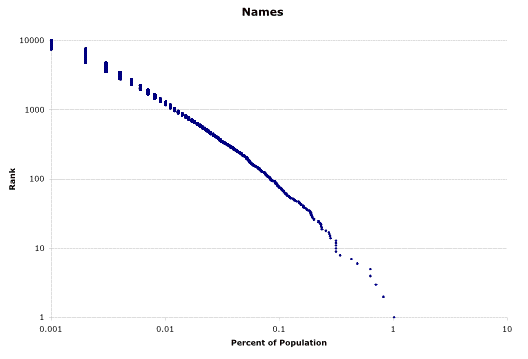
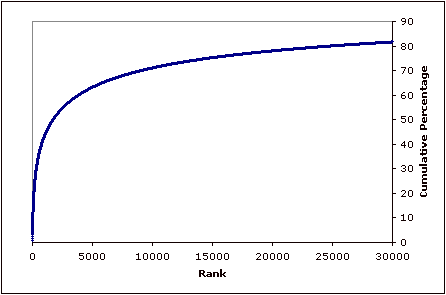
Products with network effect – it would appear – have the key aspect required to generate a power-law distribution, i.e. they link up more customers in proportion to how many customers they have already attracted. It is common to say that products with a strong network effect tend rapidly to a winner take all monopoly outcome, e.g. an extreme case of the power-law distribution.
If you are a dominate vendor in such a market differencial pricing is a critical part of your toolkit. To get (and maintain) the network effect of a large installed base you must serve users with a low willingness to pay (say residents of the third world) while conversely you want to harvest the high revenues of users who are less price sensitive (say residents of the first world).
Meanwhile you have another problem. Some users bring exceptionally high value to your network – for example in the phone system the presense of the police and fire department brings substantial value compared to the typical residencial user. Such high value members of the product network are said to complement the network. You may wish to bribe (where the price goes negative) complementary users to get the substantial value they bring into the network.
These same issues arise when attempting to get a standard adopted. The advocates of the standard, who may only desire that the network exist so they can get on with their core activities, may find it desirable to take actions to drive prices down to drive up adoption. For example contributors to the standard may find it advantagous to relinquish intelectual property rights in support of getting the standard more widely adopted.
This kind of discounting to drive adoption occurs in both large and small enterprises. With an important emerging standard we might see IP rights being relinquished to lower the barriers to wide adoption. At the other end of the scale you might see a local grocery story use discounting to bring customers into the store. In both cases the discounting serves to increase market share. Of course network effects are not the only reason to grab market share. For example, if you can capture a relationship with a customer you can often sell him more stuff. I.e. discounting may be used to capture a customer into a sticky relationship.
Of course there is always the risk of a bait and switch. A player might actively advocate the adoption of a standard. Then, he waits until the standard has achieved critical mass and a strong network effect. Finally, he proceeds to assert his IP rights – collecting a tax from the users.
In a similar scenario a vendor might sell his product at low price points to third world customers so he can reserve the option of charging them higher prices should their nations GDP grow sufficently. That’s a kind of ground cover strategy.