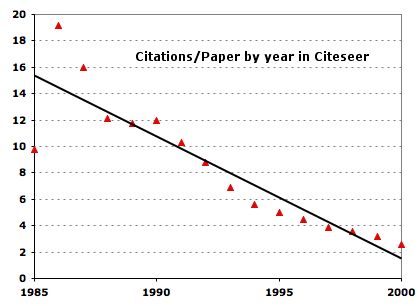
Yeah, here’s an idea. Why can’t I set my Firefox browser to distribute my search randomly across N selected search engines? That would let me continually test which search engine is coughing up the best results with the least offensive ads. It would erode the monopoly power of the search engines and increase competition. Well, why not?
Two-sided networks tend to become highly condensed, in the exaggerated case this is called “winner take all.” One driver toward condensation is the cost for players on either side to maintain relationships with two competing networks. You could own multiple computers, and run multiple operating systems, but by and large you don’t. You could use multiple search engines/portals, but by and large you don’t. The cost of coordinating two homes tends to make it unusual.
The motivation for maintaining two or more homes seem to come down to competition; but in reducing them to that we lose something. It helps to back out what the benefits of competition are. I won’t go into that, but terms like choice, reducing provider pricing power, a modicum of self regulation, and innovation all come to mind.
Motivations for multihoming are, presumably, the a vein that can be mined to find counter vialing forces to the natural tendency of two-sided networks to condense. You can then draw out those players who most strongly feel the benefit to create advocates for a less condensed market structure.
Intermediaries, middlemen again, seem like one way that can happen. The irony here is that two-sided networks are, at their heart, about reducing the cost of search out or coordination work with the population on the other sided of the network. I.e. they reduce the cost of multihoming; and enable interoperability. This irony is one of the reasons that powerful hub owners tend to swallow the intermediaries adjacent to them – the adjacent intermediaries are a source of competitive threat; not because they compete but because they can enable other competitors.
When Google pays the Firefox folks for premiere slot in the UI they are, of course, working around the problem.