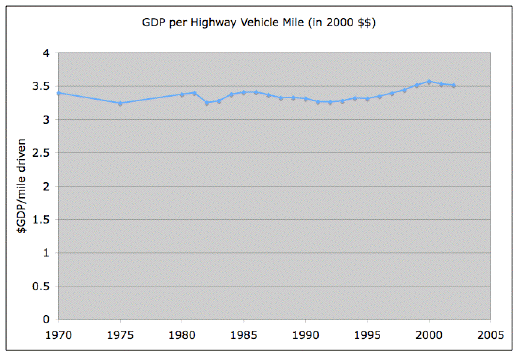
I must be wrong, but apparently there is no well tooled standard way to manage trust for digital artifacts. Consider an example: the instructions for installing Ruby’s rvm tool look like this:
curl -sSL https://get.rvm.io | bash
That’s wonderfully simple, although it implies a lot of trust in get.rvm.io!
I run into this problem a lot. For example I have scripts that help me configure virtual machines. Here’s one that installs a hyperdex that I run as I’m setting up a new machine.
cat <<'EOF' > /etc/yum.repos.d//hyperdex.repo
[hyperdex]
name=hyperdex
baseurl=http://centos.hyperdex.org/base/$basearch/$releasever
enabled=1
gpgcheck=0
EOF
yum clean all
ls -l /etc/yum.repos.d/
yum --assumeyes install hyperdex
ls -l /etc/yum.repos.d/
I then do something like this on a fresh machine:
curl http://example.com/install-hyperdex.sh | bash -
I can share these scripts, but I’d be loath to entice people into the bad habit of running such things.
And this bad habit is becoming very common. For example Continuum Analytic’s amazingly cool python data tool suite and it’s extremely useful tools for managing python versions and packages is conveniently installed by downloading a 16 megabyte shell script which you then cheerfully hand off to bash.
Of course there are systems that help with this mess. Yum will check gpg signatures, and it’s lame that says “gpgheck=0”. But why am I unaware of any tools that make it straight forward to check signatures on scripts like my install-hyperdex.sh script, or Ruby’s script for installing rvm. What I want is a tools that lets me tell users something like this:
To install Awesome-Software do this:
run-remote-script http://example.org/install-awesome-software
If you don’t have run-remote-script see how to install it by visiting …
Obviously we could ask users to step thru longer instructions.
To install our awesome software first be sure you have installed gnupg. Then download our signing key into your keyring.
curl https://example.org/our-signing-key.asc | gpg --import
Now you can download our install script and check that we signed off on it.
# Get the script.
curl -o /tmp/foo http://example.com/install-thing.sh.asc
# Verify it's signature looks ok.
gpg --verify $/tmp/foo
If that looks ok, then extract the script and run it.
sed -e '1,3d' -e '/-----BEGIN PGP SIGNATURE-----/,$d' /tmp/foo | bash -
That will work … if you don’t want users.
Why is this so damn hard? As I said at the start: we have “no well tooled standard way to manage trust for digital artifacts”. For heaven’s sake I had to use sed to extract the script!
One part of the answer would seem to be that systems like homebrew, ports, rpm, yum, etc. etc. are all trying to solve a larger problems. Which is fine, but they fail to address my problem, or the problem the rvm team has, or the problem that the python data guys have.
I have tooled up some of this, for my own needs when building virtual machines. But, it’s hardly a useful tool for others. And, it’s very much a work in progress.
Gosh, I feel like somebody must have already written a tool analogous to “run-remote-script.”