Today I noticed this ad offering to reimburse you for getting a passport. $157 per adult. I felt some sympathy for the advertiser, an island in the Caribbean. A place people go for the weekend; well they used to. The island tourism folks woke up recently to discover that numbers where down and they have discovered that the newly increased tedium of getting a passport has caused huge numbers of idle travelers to decided to, well, just go someplace else.
When my 1st son got his learner’s permit it took us three trips to the registry before we managed to accumulate enough documentation to convince them to let him have the learner’s permit. My 2nd son submitted his first pay check’s stub rather than the check and the bank called to correct the error. A bit got set on his account that didn’t get cleared. So the ATM ate his bank card. It took months to get a replacement card since his school was yet to issue the ID card they required. All N of my financial institutions have recently insisted that I add four security questions, including one involving a photograph; which is a pain since I share access to these accounts with my spouse so all 30 odd questions and their answers all have to be in some shared location. We recently got new passports, a project that was at least a dozen times more expensive and tedious than doing my taxes.
I once had a web product that failed big-time. A major contributor to that failure was tedium of getting new users through the sign-up process. At each screen they had to step through we lost of 10 to 20% of our customers. Reducing the friction of that process was key to our survival. We failed. It is a thousand times easier to get a cell phone or a credit card than it is to get a passport or a learner’s permit. That wasn’t the case two decades ago.
The Republicans have done a lot of work over the last decade to make it harder to vote; creating additional friction in the process of getting to the polling booth. The increased barriers for getting a drivers license, passport, etc. are all part of that. This make sense because now, unlike 30 years ago, there is now a significant difference in the wealth of Democratic v.s. Republican voters.
Public health experts have done a lot of work over the decades to create barrier between the public and dangerous items and to lower barriers to access to constructive ones. So we make it harder to get liquor, and easier to get condoms. Traffic calming techniques are another example of engineering that makes makes a system run more slowly.
I find these attempts to shift the temperature of entire systems fascinating. This is at the heart of what your doing when you write standards, but it’s entirely scale free. Ideas like this are behind the intuition of some managers who insist on getting everybody in the team working in the same room with no walls between them.
In the sphere of internet identity it is particularly puzzling how two counter vialing forces are at work. One trying to raise the friction and one trying to lower it. Privacy and security advocates are attempting to lower the temp. and increase the friction. Thus you get the mess around the passport, real-id, and the banks. Wearing that hat it seems perfectly reasonable that one should present photo id when you vote, or have your biometrics captured if you cross a boarder. On the other hand there are those who seek in the solution to the internet identity problem a way to raise the temperature and lower the friction. That more rather than less transactions would take place. That more blog postings garner good coments, that more wiki pages will be touched up, that more account relationships will emerge rather than less.
Of course the experts in the internet identity space are trying to strike a balance. It’s clearly one of those high-risk high-benefit cases that people have trouble holding in their head.
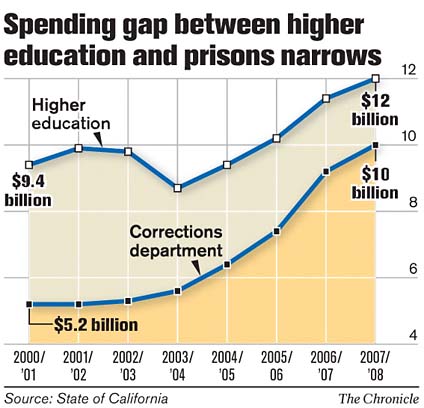
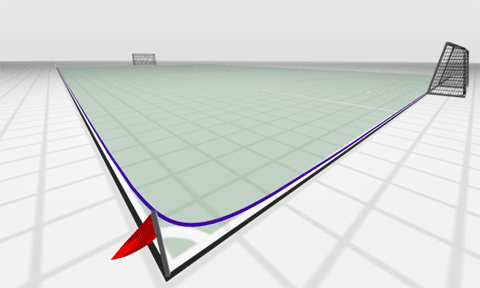
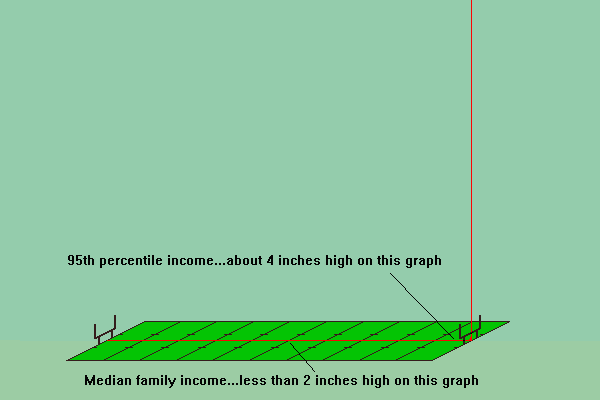
 Both of these do a nice job of helping to visualize the actual shape of these curves. They help to clarify why the politics and business models that serve the two legs are very different and why the appeals that emphasis middle class values are should be treated with some suspicion. The more typical illustration, shown to the right, is preferable if you want to deemphasis the polarization and highlight the uniformity of the underlying generative processes.
Both of these do a nice job of helping to visualize the actual shape of these curves. They help to clarify why the politics and business models that serve the two legs are very different and why the appeals that emphasis middle class values are should be treated with some suspicion. The more typical illustration, shown to the right, is preferable if you want to deemphasis the polarization and highlight the uniformity of the underlying generative processes. This morning I was attempting to read, yet again,
This morning I was attempting to read, yet again,  I had already noted many of the motivations outlined above for sharing one’s talents: countering the guilt for letting it go to waste, the positive emotions of generosity, the low cost of giving away the excess capacity. But I had not noticed something else: skills that are not exercised decay. While the hotel room left idle depreciates only slightly, a skill unused decays quickly. The skill demands that I exercise it, it’s survival depends on that exercise. If I horde it, it evaporates.
I had already noted many of the motivations outlined above for sharing one’s talents: countering the guilt for letting it go to waste, the positive emotions of generosity, the low cost of giving away the excess capacity. But I had not noticed something else: skills that are not exercised decay. While the hotel room left idle depreciates only slightly, a skill unused decays quickly. The skill demands that I exercise it, it’s survival depends on that exercise. If I horde it, it evaporates.