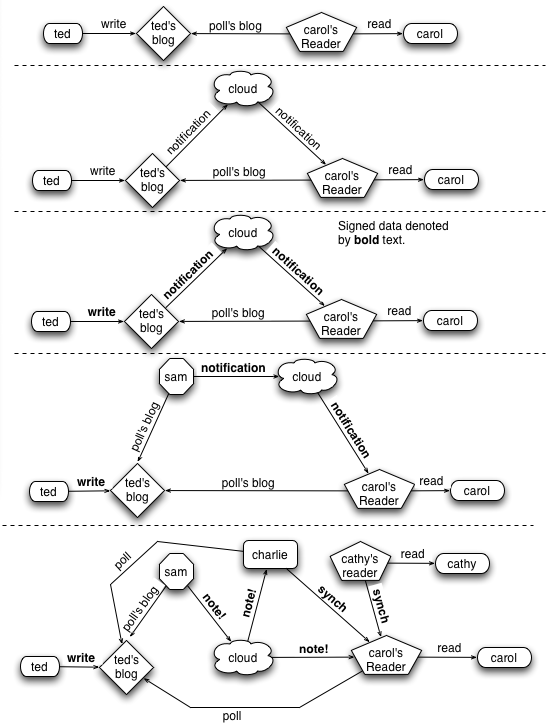
Jim Winstead wrote a nice note on “decentralized web(site|log) update notifications and content distribution.” He plays some cards into the design game that I found fun to toy with. One of these cards the cloud. The idea being that as blogs update things (notifications of update, entire postins) are injected into the cloud. Blog readers tap into the cloud to gain access to that traffic. Signatures is another card he plays; this draws our attention to the spam problem – for example bad actors posting false notifications about other people’s blogs.
Here some commentary from the sidelines.
On the input side: Better I think if a distinction is made between asserting that Ted:actor wrote P:posting v.s. Sam:actor inserted P:posting into the cloud.
Interesting challenge: how to the avoid condensation of the cloud into a small number of players. Splitting the Sam set out from the Ted set actually encourages condensation.
Inside the cloud: How much persistent state is in the cloud and how out of synch that can become from the origin data?
One branch in the design space makes the cloud is just a notification mechanism. That’s tempting and seems at like the right choice. Understanding if it’s a workable choice demands that we understand what the recipients of these notifications are doing with the data.
Each client Carol of the output of the cloud is maintaining a model of N data sources. After service interruptions the clients have to bring their model back into synch. They might just go poll the original sources, or they might patiently wait for the cloud to send them additional notifications. They can also work with other players who also have models, e.g. their peers Cathy or specialized caching middlemen Charlie.
The real design problem here is “collaborative model synchronization.” The service interruptions are what allows the models to get out of synch. Some of those service interruptions are apparent – i.e. you were off line – some of them aren’t – i.e. a unknown portion of the cloud was offline.
Watch dog timers are the usual means by which a client becomes suspicious that a service interruption has taken place in some unknown portion of the cloud. That implies a background of dogs barking. Who signs these barks? You want the dogs as close to the edge as possible, i.e. outside the cloud. Sam obviously barks. But what about Cathy and Charlie? If we are collaborating with them in our model synchronization they clearly need to bark as well. When they fall silent we can then go seek other model maintenance collaborators.
Two other issues come to mind. How critical is is to merge multiple atomic updates into single messages. How much privacy can we offer the cloud’s listeners? If I subscribe into the cloud for updates I’m revealing too much information about my reading habits. To whom? Cathy and Charlie at least and of course to the cloud P2P presence scheme. Both these issues will need work.
In once sense this isn’t a new problem. The real time control industry has lots of design patterns for how to distribute and keep models in synch across the many machines that are doing the control. Expert systems are full of analogous design patterns for inferring models via backward and forward chaining. The scale, privacy, spam, and reputation issues add spice to this version of those problem.
I often use the term “pedigree” when discussing problems of this kind. Because in many cases the data at hand traveled. It passed thru various hands. It underwent some number of transformations. It took some time to get here. I expect we will see an explosion of scrapping over the next few years. Well maybe we shouldn’t call it scraping, maybe we should call it automated data representation transforming. Signatures help to remove some of the reasons you need a pedigree, but not all of them. If your data about Ted’s site came via Sam, thru the cloude, via’s Cathy cache’d model your are happy that Ted signed the posting. But to know why how it came to be four hours late you want at least Sam and Cathy to extend the pedigree.
Fun problem.
Hm, interesting I wrote about this almost exactly a year ago.
Pingback: As I May Think...