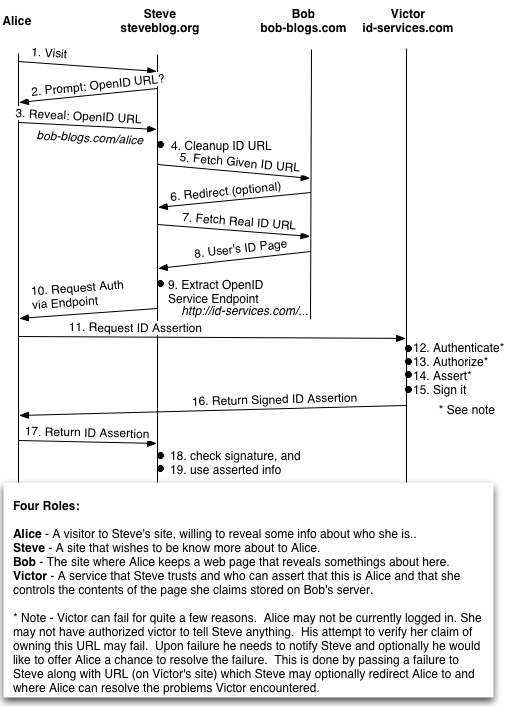
I was confused about OpenID. This posting is second run at explaining how it works. Hopefully I’ll get it closer to right this time. (Nope, it’s not quite right yet.)
Like most identity systems we have three parties in the story. The user, a site that can ID the user, and a site that would like to know the user. It helps to personify these.
- Alice – the visiting user.
- Steve – the site Alice is visiting that wishes to know Alice.
- Victor – a site that knows Alice and can introduce her to Steve.
I think of Steve as suspicious and Victor as able to vouch for Alice.
In OpenID Alice is denoted by a URL, typically her blog’s URL, and then Victor helps Steve to be sure that when Alice actually owns the URL she claims.
The protocol is simple.
- Alice, via her browser, visits Steve.
- Steve asks Alice to reveal her URL, so he can get to know her better.
- Alice tells Steve her URL.
- Steve fetches that page.
- Steve finds a pointer to Victor’s service on that page.
- Steve works with Victor (via Alice’s browser) to check the URL.
- Victor provides Steve with a signed statement: “This URL is owned by the person currently signed on with Victor via this browser.”
This design has a number of options that aren’t obvious at first glance.
For example Alice might enter a URL that triggers a series of redirects before it finally generates a page. So she might enter alice.isp.com and the redirects could lead to http://alice.isp.com/homepage.html. The URL of page that is finally retrieved is used to denote Alice. This helps to normalize the URL used to denote Alice, but it also provides the chance to do some clever things.
Denoting Alice with a URL can be bad. Important ID safety I do not hand out global identifiers! It encourages revealing a lot more about Alice to Steve than Alice may desire, and it can make it easy for information about Alice to be aggregated from Steve and others like him. There is a work around for this, but it’s a bit unnatural.
Normalizing the URL could be used to work around this. If Alice enters is logged in at isp.com and enters id.isp.com then it the redirect could return http://id.isp.com/anonymous/for-steve/234145. All this reveals about Alice is what appears on that page, and that she has an account with isp.com.
I must admit the work around is beginning to grow on me. That thing (i.e. http://id.isp.com/anonymous/for-steve/234145) is what’s known in the trade as an opaque id for Alice; getting it out in the open has some advantages.
Another point to make is about Victor. Victor’s job is to introduce Alice to Steve, that’s it. He doesn’t need to run Alice’s blog, or host her pages. Alice doesn’t even need a blog. In one scenario Victor might work at Technorati; Technorati already has a page for every blog including Alice’s. If Alice gets an account at Technorati and claims her blog then she then Technorati knows enough to be her vouch for her. In another scenario Alice doesn’t even need a blog, she just needs an account with some site that’s willing to play the role of Victor.
The service that Victor offers to Steve is very limited in the current version of OpenID. Victor signs a statement: “The user denoted by this is currently signed on at my site via the browser in question.” Steve can check that signature by using Victor’s public key. Steve can grab the key from Victor’s web site.
Currently the design is only as safe as the Steve’s ability to get Victor’s public key, trust it, and trust Victor. The design doesn’t dig into these issues very deeply.
The design does not include a way to check Alice’s reputation, or tarnish it if she misbehaves. So if Alice isn’t a spammer she doesn’t get to accumulate karma for her good behavior; nor does it provides a way to revoke that karma if she suddenly turns into a raving loon. Of course one man’s loon is another’s endangered species; or in other words reputation is very contextual. If Alice’s ID URL is valuable to her that helps some.